数据库规范 V1.1
指南目的
为了在软件生命周期内规范数据库相关的需求分析、设计、开发、测试、运维工作,特此建立一份基于Mysql的使用规范,本规范不仅是开发也包括使用规范。目前我们推荐使用的数据库版本为Mysql5.7.x。本文档适用于运营开发部的所有项目。
查询工具及版本的推荐
数据库设计
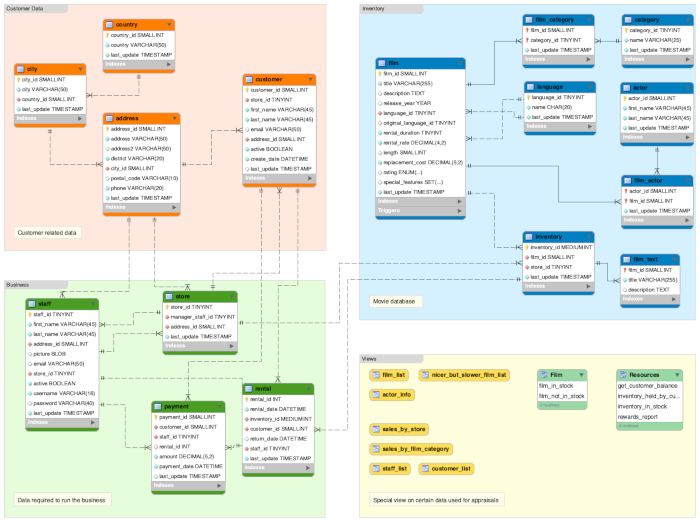
数据库设计阶段推荐使用MySQL Workbench自带的Models工具,直观免费。
线上数据库查询
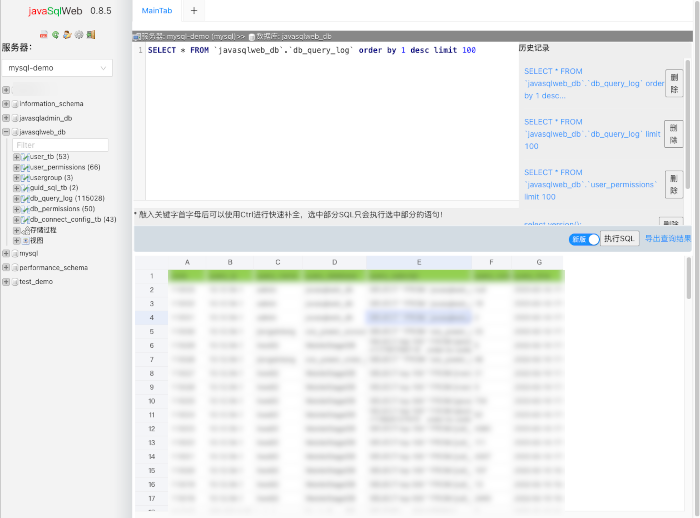
线上数据库默认不开直连权限,请通过开发部WEB工具进行数据查询。开通权限请联系你的主管。
规范
- 非特殊情况下,请使用INNODB存储引擎
- Mysql的存储过程、函数、触发器并不成熟,不建议使用
- 主外键关系只停留在设计阶段和程序内,不要数据库中做外键约束
- 做表关联时关联的字段类型一定要是一致的,字符编码集也要一致。utf8和utf8mb不是一个编码集,做关联时索引不会生效请注意。
- 命名只使用字母、数字、下划线,单词中间使用下划线进行分割。不要出现大写字母
- 超过100万条记录的表增加字段/索引请先和DBA进行确认,是否需要在下次停机维护时增加。
- 库名、表名、字段名支持最多64个字符,建议不要超过36个字符
- 库名、表名、字段名禁止使用MySQL保留关键字
表设计规范
- 四种类型表名
- 业务实体表使用_tb做为表名结尾,紧急迁移时不可丢弃
- 非业务实体但与业务需要在同一事务中的使用_tb做为结尾。紧急迁移时可以丢弃的
- 日志相关的表,包括重要接口日志。使用_log做为结尾。随时可以清理丢弃
- 业务变更表(xxx_history_tb),核心业务数据的历史变化记录,可能需要与主业务表在同一个事务内。 例如:账户余额的表更历史,配置表的变更历史等。 所有的配置表需要配置表和配置历史表 配置表是配置当前最新的配置 配置历史表记录配置每个版本内容,表结构和配置表一致,每次对配置修改的时候同时往历史表里新增一条记录 对于系统核心重点关注的内容,例如账户余额,手机号、以及复杂的业务订单需要记录订单状态或重要事件变更历史
- 所有表至少包含创建日期字段,对于需要更新的业务表需要额外增加修改日期字段切非空。
- 所有表必须有主键,尽量使用自增字段,推荐Int类型,数据量大的应该使用bigint。
- 当表字段数过多时(>15),可分成两张表,一张做为条件查询主表,一张做为详细内容表。
- 枚举类型表请不要使用int类型,请使用varchar把枚举的具体字符值插入表中
- 为了便于其他人的理解,所有字段请包含注释。创建正式表时也要包含备注字段
- 对于程序上就要保持唯一的字段,请加上唯一约束并以_uk结尾
- 当单表数据大于500万条时考虑要进行归档或分表。归档表名为 原始表名_年月日_bak 命名
- 表中禁止直接存储文档,请使用对象存储。将URL存入表内
- 做为where条件查询的列必须是NOT NULL,有空值的列索引会有问题。
- 尽可能把所有列定义为NOT NULL,索引NULL列需要额外的空间来保存,所以要占用更多的空间,进行比较和计算时要对NULL值做特别的处理。
- 时间类型字段建议使用datetime类型,并精确到毫秒
- 字段禁用Bit类型,建议使用tinyint(1)代替
- 字段名不能以is开头。避免程序序列化问题
- 无特殊需求尽量不要用json字段
- 禁止在表中建立预留字段,后续修改类型会锁表。
索引设计规范
索引是一把双刃剑,可提高查询效率,但也会降低插入和更新的速度并占用磁盘空间。
- 索引以idx开头,后面跟字段名,使用下划线分割,例如:idx_phone
- 单张表中索引数量不超过5个
- 单个联合索引中的字段数不超过5个
- 联合索引顺序选择:
- 区分度最高的放在联合索引的最左侧(区分度=列中不同值的数量/列的总行数);
- 尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO性能也就越好);
- 使用最频繁的列放到联合索引的左侧(这样可较少的建立一些索引)。
- 避免冗余或重复索引
- 索引列建议:
- 出现在SELECT、UPDATE、DELETE语句的WHERE子句中的列;
- 包含在ORDER BY、GROUP BY、DISTINCT中的字段;
- 多表join的关联列
- 索引使用建议:
- 不使用%前导的查询。例如
like '%xxxx',无法使用索引 - 不使用反向查询。例如not in / not like
- 避免sql中数据类型的隐式转换。例如
where id = '13' - 避免where中在字段前使用函数进行匹配。 例如
where date_format(create_time,'%Y-%m-%d') = '2023-11-28' - 用explain查看执行计划
库设计规范
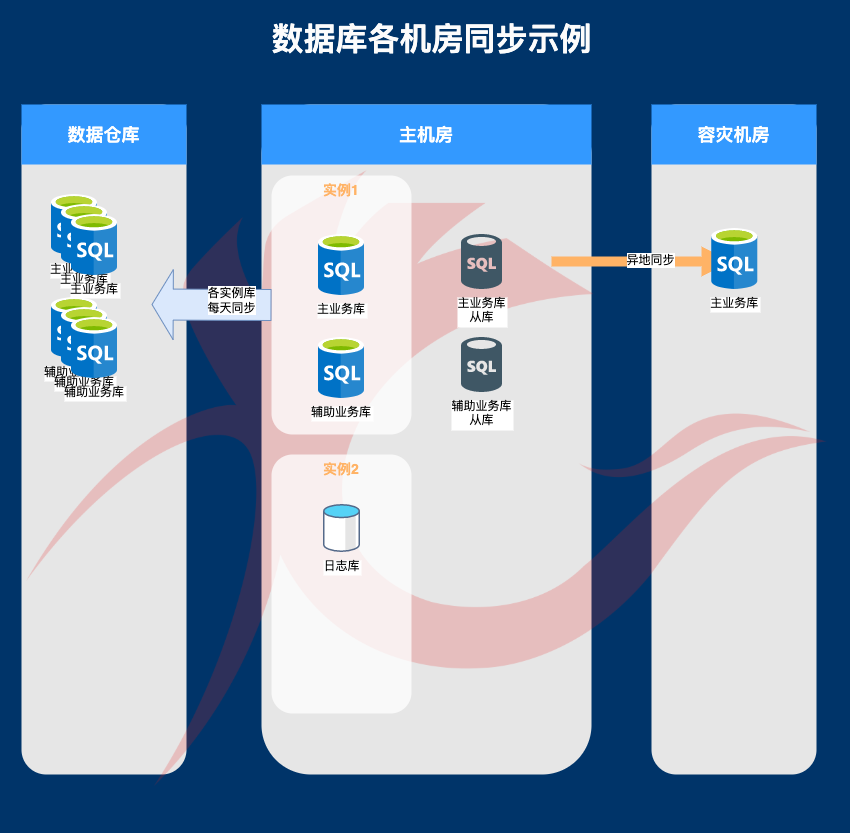
- 同一业务数据库也建议分为三类,主库、辅助库、日志库
- 主库与辅助库会保证在同一实例上,允许在同一事务内。
- 主库建议命名为 业务_main_db。主库内只放第一类数据表。主库为同时做本地同步库和异地同步库
- 辅助库建议命名为 业务_assist_db。辅助库只放第二类数据表。辅助库只会在本地做同步库
- 日志库建议命名为 业务_log_db。日志库不做任何同步操作,理论线上业务也不应读取日志库内数据
开发规范
- 程序内不应有创建、删除、修改、截断表的操作语句。以上都应通过工单形式找DBA进行操作
- 程序内不要出现select *,要指明具体字段
- 线上程序不要使用 模糊查询,会非常影响性能
- 目前springboot项目的数据库连接池推荐为druid-spring-boot-starter的1.1.20版本
- 禁止在主库上执行统计类操作,请在从库上执行。如果要关联多个实例下的表,请在汇总服务器上执行
- 当需要进行in查询时,in中包含的值应少于1000个
- 对于已经有大量数据的业务表,新增SQL时请使用explain进行试探分析
- 对应同一列进行or判断时,使用in代替or
- 避免使用子查询,可把子查询优化为join操作
- 通常子查询在in子句中,且子查询中为简单SQL(不包含union、group by、order by、limit从句)时,可以把子查询转化为关联查询进行优化
- 子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能 会受到一定的影响;
- 由于子查询会产生大量的临时表也没有索引,所以会消耗过多的CPU和IO资源,产生大量的慢查询
- 拆分复杂的大SQL为多个小SQL(大SQL:逻辑上比较复杂,需要占用大量CPU进行计算, SQL拆分后可以通过并行执行来提高处理效率。)
- 避免使用JOIN关联太多表(最多不超过5个)
- 禁止在数据库中存储明文密码
- 所有存储相同数据的列名和列类型必须一致
- 建议使用服务器时间而非数据库时间进行存储
- 对单表的多次alter操作必须合并为一次操作
- 修改索引时应该先新建索引,然后再删除索引
数据库同步规划示例